Filtering FriendFeed – How Crowdsourcing Can Solve This
June 1, 2008 15 Comments
It would be nice to have filters on FriendFeed. For instance, it would be nice to be able to hide any post containing the word “Obama” without having to hide someone’s other stuff. Or the ability to hide any entry containing the word “ubuntu”, etc.
Thomas Hawk, FriendFeed direct post, May 1, 2008
The need for filters on FriendFeed is a recurring topic. Click here to see the numerous entries that contain the words ‘friendfeed’ and ‘filters’. Louis Gray notes the need for this in a recent post.
I want present an idea for filters that has two pieces:
- Category filters
- Keyword filters
The two pieces are interrelated, and crowdsourcing will be used to build out the category filters.
Let’s get to it, shall we?
Category Filters
FriendFeed already has a “Feed Preferences” page for each member. Here is where you can manage your category and keyword filters. The graphic below is mockup of this:
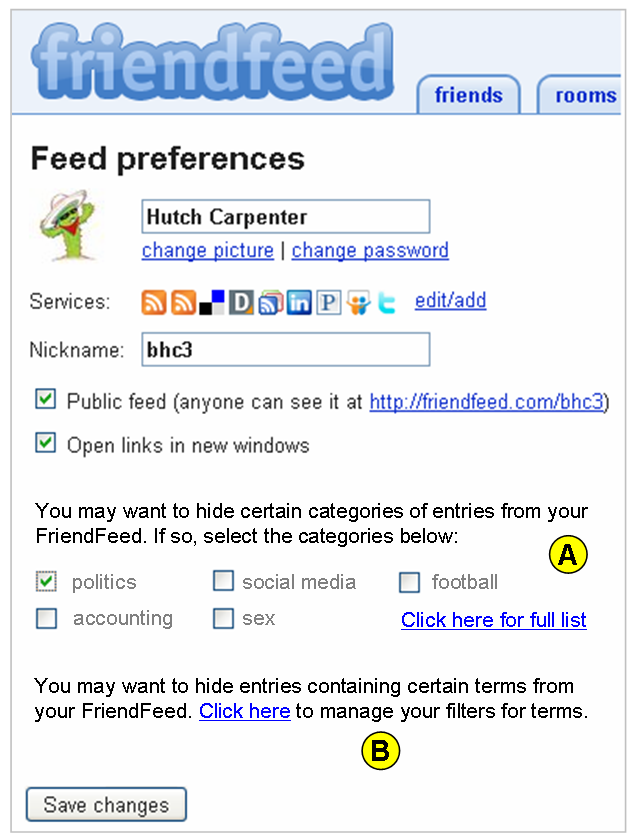
A. Category Filters
Various categories will be displayed, along with a link to the full list of categories. In the example, above, I say that I’d like to filter out all FriendFeed entries that relate to politics.
The value of category filtering is that it prevents you from having to manage every keyword that might relate to a category. In a recent post, I noted Dave Winer’s 38 different politics-related terms. For instance, he used the terms: Hillary, HRC, Clinton, Edwards, Obama, Rove, etc. Having the ability to automatically filter those out without having to set up keyword hides over and over would be a great benefit to many members. Particularly as FriendFeed gains traction with a flood of new members.
Now how would FriendFeed know that Hillary, Obama, HRC, etc. are part of the politics category? Keep reading.
B. Keyword Filters
Members will need the ability to see what words they have hidden. They can un-hide keywords, or add new keywords to hide directly on the Feed Preferences UI.
Keyword-Based Hides
FriendFeed currently supports hiding specific entries, plus entries from specific members and services. For instance, you can hide all Twitter updates. What is lacking is the ability to filter out entries with specific terms in them.
For instance, shown below are three tweets from Dave Winer regarding politics:

What I’d like to do is apply the Hide function to anything with ‘Harold Ickes’ or ‘Henry Waxman’. This is a mock up of that screen below:
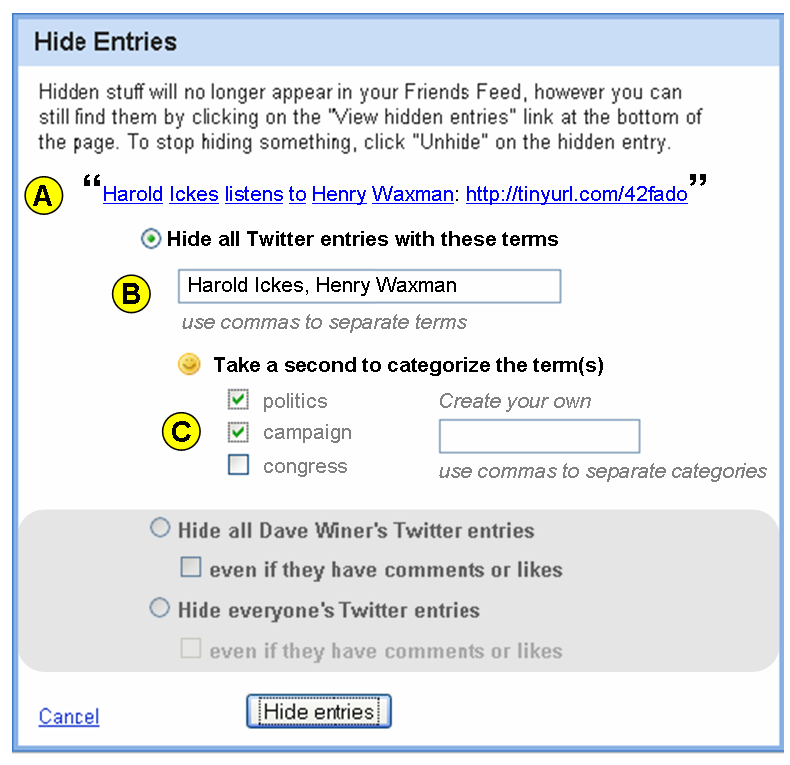
A. Full Text of Entry Displays
The full text of the entry appears. Each word of the entry includes a link. The links are easy ways for members to populate the ‘hide terms’ input box.
B. Hide Terms Input Box
Commas separate each term.
C. Categorize the Terms to Be Hidden
As the member hides the terms, they will be asked to apply a category. The most popular categories previously applied to the keywords will be displayed. Or the member can type a category into the input box, and FriendFeed will auto-suggest different categories with each character entered.
Why do this? This is the basis of the crowdsourced solution.
Let the People Decide
People will have a much better handle on the categories that apply to a keyword than will a heavy-duty algorithm. Such human filtering is the basis of tagging.
Two elements are relevant here:
- The need to prevent bad categories being assigned to keywords
- The motivation to do this categorizing
Use Bayesian Stats to Prevent Bad Categories
Here’s the issue you want to avoid. Some prankster assigns the football category to the term “Paris Hilton” while hiding all entries containing her name. Suddenly, members who are filtering out football entries stop seeing their Paris Hilton updates (yes I know, horrors…).
Enter Bayesian statistics. Carl Bialik, a columnist for the Wall Street Journal, has a great column on the use of Bayesian stats for online ratings. The gist of this approach is that all items in a rating system are born with identical ratings. Their ratings only change as people vote, and it takes a sufficient number of votes to really move the rating of an item. Here’s an example of this from the WSJ column:
For instance, as noted in the column, IMDB.com doesn’t use straight averages to list the top 250 movies of all time, as voted on by its users. Instead, each movie starts out with 1,300 votes and a ranking of 6.7, which is the site’s average. That helps smooth the effects of a few intense votes; it takes a lot of votes to budge the IMDB meter up or down from 6.7
That same approach would be applied inside FriendFeed. It would take a large number of people putting a keyword into the same category before the keyword actually became “part” of that category.
Once a keyword graduates to a category, any users filtering that category won’t see entries with those keywords.
Motivation
Why would anyone bother to categorize the keywords they hide? One answer – not everyone will. But there are two drivers of members doing some keyword categorization.
First, members need to recognize that they are contributing to a system from which they are likely benefiting. If you filter any category, you will be benefiting from the work of others’ who have categorized keywords.
Second, the categorization experience has to be simple and fast. You’ve got the member right there, motivated to hide a term. Make it easy for them to channel that motivation into a simple categorization. The most popular previous categories are displayed, making it easy check them. And the auto-suggest feature can be done fairly quickly. I like how Faviki is doing it:
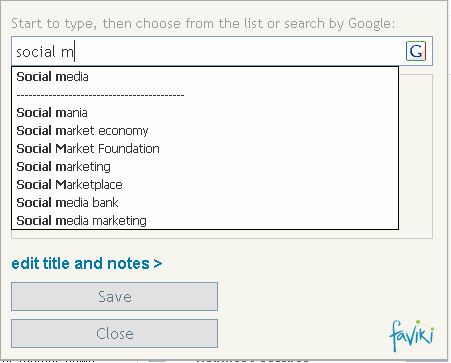
Faviki draws from thousands of different Wikipedia entries for this list.
Final Thoughts
One thing to consider here is that every entry coming into FriendFeed would need to be filtered for keywords. Serious processing power will be required. Fortunately, the FriendFeed guys have firsthand experience with high volumes of real-time queries for keywords at Google.
With regard to this proposal, I haven’t (yet) seen anything on the market that will provide the category tags that would help filter FriendFeed. Since it’s the members who are most in tune with what they want to filter, their common sense and motivation should be leveraged.
As FriendFeed grows, imagine new members easily managing the flow of information by simply filtering the politics category rather than having to set up an extensive list of new keywords. It would make the experience that much better for everyone.
*****
See this item on FriendFeed: http://friendfeed.com/search?q=%22Filtering+FriendFeed+-+How+Crowdsourcing+Can+Solve+This%22&public=1



















The Conversation